H.G.O.D. · 10. Juni 2026 · 3 min read
MABOTO ist online. Marktbeobachtung, ortskonkret per PLZ, händlerübergreifend, mit Live-Demo unter maboto.de und dem vollständigen Code unter github.com/Jeuners/maboto. Das ist die Oberfläche. Worüber ich heute schreibe, ist nicht das Produkt, sondern die Methode dahinter — der Grund, warum das Repo seit dem ersten Commit als Architektur-Referenz markiert ist und nicht als Marktbeobachtungstool.
Der Schnitt
Wer “KI-Aufgabe” hört, denkt: Modell holt Daten, Modell sortiert Daten, Modell zeigt Daten. Drei mal Modell. Dass das nicht funktioniert — mit erfundenen Preisen, halluzinierten Händlern, plausibel aussehenden Märchen — ist seit zwei Jahren bekannt. Trotzdem werden weiter Tools gebaut, die genau diesen Weg gehen.
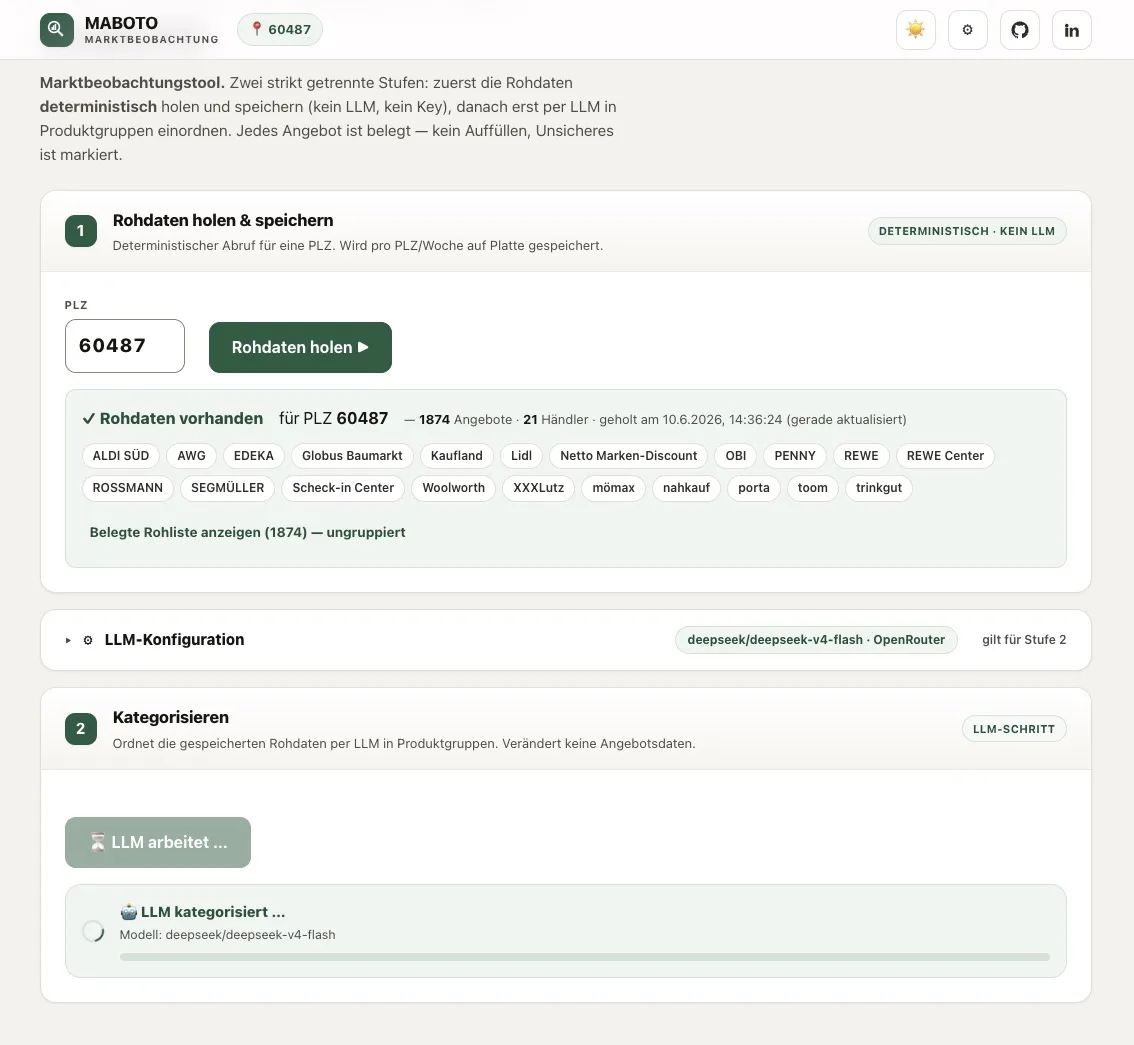
MABOTO zerlegt die Aufgabe in zwei Teile, die strikt getrennt bleiben:
- Daten holen — Preise, Gültigkeiten, Händler an Ort X. Reproduzierbar, exakt, gehört ohne Ausnahme dem deterministischen Code. HTTP-Request und Parser. Kein LLM.
- Kategorisieren — ist Toffifee Süßware? Gehört eine Blühpflanze in eine Lebensmittelliste? Echte Ambiguität, echtes Sprachverständnis, gehört dem LLM. Und nur dort.
Im Code ist dieser Schnitt nicht verhandelbar: Der Fetch-Teil enthält keinen einzigen LLM-Aufruf, ein Test in tests/ prüft genau das. Wer den Schnitt einreißt, scheitert beim CI-Run, nicht erst im Produktivbetrieb.
Prüfbare Bedingungen statt höflicher Bitten
Eine Regel, die als Prompt-Höflichkeit formuliert ist — “bitte keine erfundenen Preise” — bricht still weg, sobald das Modell unter Last gerät, einen schlechten Tag hat oder mit einer neuen Version anders entscheidet. MABOTO hat drei harte Regeln, die als Code-Bedingung im Datenfluss stehen, nicht im Prompt:
- Kein Auffüllen. Keine belegten Angebote für eine Gruppe → “keine Daten”. Nie ein plausibles Beispiel als Lückenfüller.
- Nur Belegtes. Preis, Gültigkeit, Händler stammen aus dem Datensatz, nicht aus dem Modell. Fehlendes Feld bleibt fehlend, wird nicht geraten.
- Abbruch statt stiller Drift. Gibt die Datenlage die Anforderung nicht her, bricht das Programm mit klarer Ursache und Vorschlag ab — statt ein “irgendwie vollständig aussehendes” Ergebnis zu liefern.
Das System sagt, wenn es scheitert. Nicht aus Einsicht des Modells, sondern weil eine externe Bedingung es erzwingt.
Der Cache friert KI ein
Jedes vom LLM eingeordnete Produkt landet in einem SQLite-Cache (titel+marke → gruppe, modellagnostisch). Beim nächsten Lauf überspringen bekannte Produkte das LLM komplett. In der Praxis sinkt die LLM-Last über die Wochen drastisch — bis ein kleines, billiges Modell für die wenigen Neuzugänge reicht. Eine manuelle Korrektur fließt als stärkstes Cache-Signal zurück (modell="manuell"); das Produkt ist danach nie wieder unsicher.
Daraus folgt eine Eigenschaft, die in dieser Klasse von Tools selten erwähnt wird: KI wird über die Zeit überflüssig. Nicht weil sie versagt, sondern weil sie ihre Arbeit zwischengespeichert hat.
Ehrlich über Grenzen
Lokale Modelle (3-9B über Ollama) liefern für diese Batch-Tool-Calling-Aufgabe oft kein zuverlässiges Ergebnis. Das System rät dann nicht, sondern markiert alles als “Sonstiges/unsicher”. Der Mangel ist sichtbar, nicht kaschiert. Cloud-Modelle über OpenRouter (Default DeepSeek v4 Flash, ~1-2 Cent pro Lauf) machen den Job verlässlich.
Discounter-Abdeckung wird datengetrieben ausgewiesen, nicht behauptet. Die pauschale Annahme “Aldi/Lidl fehlen bei Aggregatoren” wurde von den echten Daten widerlegt — also steht sie auch nicht im Code.
Was MABOTO eigentlich ist
Kein Produkt. Eine Tech-Demo, MIT-lizenziert, FastAPI im Backend, klare Adapter-Schnittstelle für weitere Datenquellen. Erster echter Adapter spricht marktguru an, respektiert robots.txt, drosselt sich, bricht bei fehlender Erlaubnis sauber ab. Bildungs- und Recherche-Projekt, kein SaaS.
Die Test-Suite prüft Architektur-Regeln, nicht nur den Happy Path: Schnitt-Test (kein LLM im Fetch-Teil), Daten-Integrität, Unsicherheits-Flag, Cache-Verhalten, Korrektur-zu-Cache-Schleife, Anbieter- und Retry-Logik, Web-Endpoints. Volle Suite offline, ein E2E-Test mit Playwright deckt die Browser-Persistenz ab. CI bei jedem Push.
UI hell und dunkel adaptiv, volle Tastaturbedienung, WCAG-AAA-Kontrast (≥7:1), automatisiert mit axe-core geprüft. Barrierefreiheit ist hier nicht Marketing, sondern Test-Bedingung.
Wofür das die Referenz sein soll
Jedes Mal, wenn jemand fragt “Wie setzt man KI eigentlich richtig ein?”, geht der Verweis künftig auf dieses Repo. Nicht weil Marktbeobachtung besonders wichtig wäre, sondern weil die fünf Punkte universell sind:
- Trenne deterministisch von ambig.
- Verankere Qualität als prüfbare Bedingung, nicht als Prompt-Wunsch.
- Lass die KI ihre eigene Arbeit zwischenspeichern, bis sie selbst entbehrlich wird.
- Markiere Unsicheres als unsicher, statt es zu kaschieren.
- Halte den Menschen im Loop, mit sichtbarer KI-Arbeit und direktem Korrektur-Pfad zurück in den Cache.
Wer 2026 noch Tools baut, in denen das LLM die HTTP-Requests macht und der Mensch danach den Schaden aufräumt, hat die Architektur nicht verstanden. KI ist eine Schicht. Kein Ersatz für Code.
Live: maboto.de Quellcode: github.com/Jeuners/maboto — MIT Mitentwickelt mit: Timo Weil
Leave a Reply